Урок 2: Внутри поисковой системы: от запроса до выдачи (18 мин.)
смотреть видеолекцию: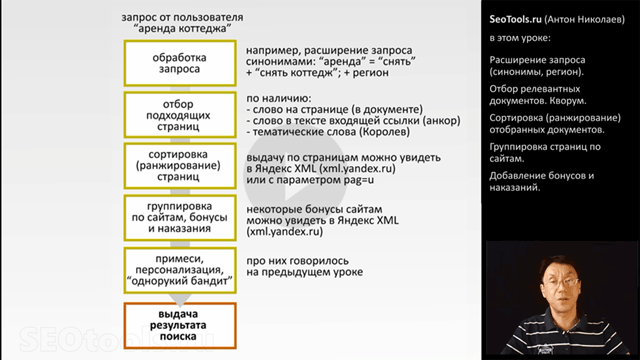
КОНСПЕКТ УРОКА:
Добрый день, сегодня мы продолжим изучать поиск. На прошлом уроке я вам показывал, как и почему различается выдача поисковых систем по одному и тому-же запросу, но для разных пользователей. Сегодня мы начнем разбираться с внутренним устройством поиска.
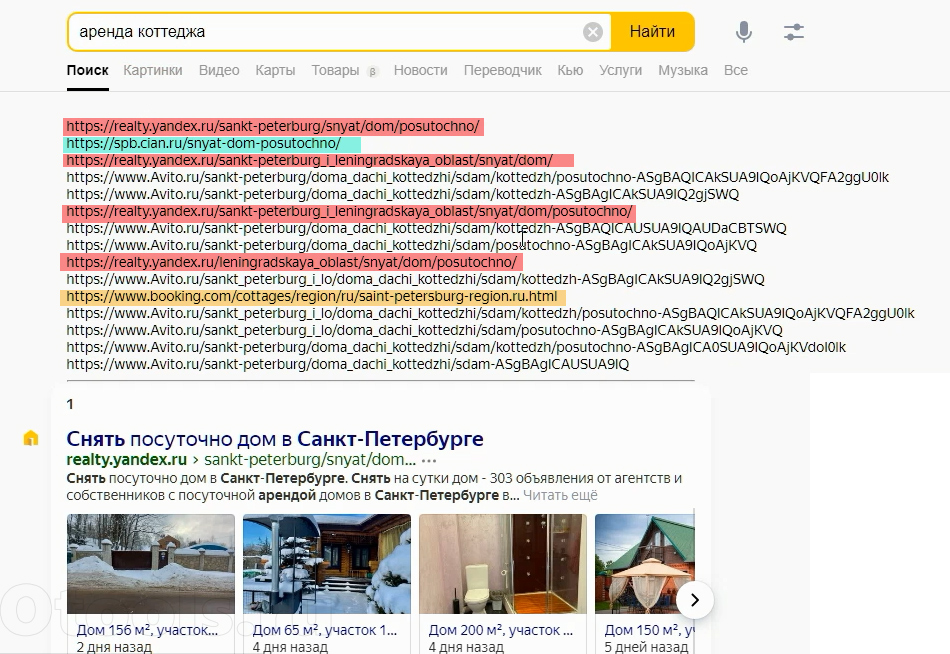
Перед вами на экране картинка из инструкции Яндекса (с добавкой блока пост-обработки), которая раскрывает как и что происходит на пути от запроса к выдаче внутри поиска.
1. Пользователь вводит поисковый запрос.
2. Этот запрос попадает в блок обработки запроса, где с этим запросам что-то делают. Например, добавляют к исходному запросу дополнительные слова. В результате запрос идет дальше не в том виде, в котором его ввел пользователь.
3. Третий блок - это блок сравнения с популярными запросами. Для популярных запросов в Яндексе хранится уже готовый набор лучших документов. Которые тут же и выдается.
4. Если запрос был не столь популярный, то он поступает на несколько различных серверов. Их результаты поиска ранжируются по технологии Matrixnet (новая версия называется CatBoost).
5. Список отранжированных документов подвергается дополнительной обработке и попадает на компьютер пользователя.
1. ИЗМЕНЕНИЕ ВВЕДЕННОГО ЗАПРОСА ДО ПОИСКА
Посмотрим глубже на эти процессы. На данной схеме представлена модель, удобная для понимания. В качестве примера, от пользователя поступил запрос "аренда коттеджей":
Перед нами Яндекс, я завожу сюда запрос "аренда коттеджей".
Яндекс расширяет запрос из с учетом синонимии слов "аренда" и "снять". Т.е. он будет искать не только документы, которые относятся к "аренде коттеджей", но и документы, которые относятся к словам "снять коттедж".
Для региональных запросов Яндекс расширяет запрос на название региона.
Поскольку у меня стоит регион Санкт-Петербург, Яндекс расширил на название региона "Санкт-Петербург" и выделил жирным шрифтом. Таким образом он искал документы, в которых содержатся не только слова "аренда" (и "снять") "коттедж", но и название региона "Санкт-Петербург".
Ищем, вот у нас результаты поиска: Яндекс выделяет жирным шрифтом слова запроса в найденных документах, во фрагментах текста найденных документов. Вот здесь выделено "аренда коттеджей" и в заголовке страницы тоже выделено "аренда коттеджа". Кроме того, Яндекс расширил этот запрос по синонимии "аренда - снять" и выделил еще и слова "снять". Здесь - в заголовке страницы, здесь тоже заголовки и в тексте, здесь и здесь.
Есть упоминания и о более сложных алгоритамх расширения запросов: "Слова запроса можно расширить близкими им по смыслу (синонимичными) словами или фразами. Либо вместо исходного запроса пользователя взять другой, который сформулирован иначе, но выражает схожую информационную потребность. Например, для запроса 'отдых на северном ледовитом океане' похожими могут быть:
- 'можно ли купаться в баренцевом море летом'
- 'путешествие по северному ледовитому океану'
- 'города и поселки на побережье северного ледовитого океана'
(Это реальные примеры расширений запроса, взятые из поиска Яндекса.)
Как найти похожие слова и запросы — тема отдельного рассказа. Для этого в нашем поиске тоже есть разные алгоритмы, а решению задачи очень помогают логи запросов, которые нам задают пользователи."
2. ОТБОР РЕЛЕВАНТНЫХ ДОКУМЕНТОВ
Следующий этап в работе в поисковой системы - это отбор в базе документов, подходящих для ответа на запрос. В простейшем виде можно представить, что отбираются те документы, в которых встречаются слова запроса.
КВОРУМ С УЧЕТОМ ВЕСА СЛОВ ЗАПРОСА
На самом деле происходит немножко сложнее. Сейчас я вам покажу на примере запроса "аренда коттеджа в Савитайпале". "Савитайпале" - это небольшой городок в Финляндии.
Отдельные слова запроса встречаются в базе Яндекса с разной частотой. "Савитайпале" - более редкое слово, чем "аренда" и "коттеджи". За счет наличия редкого слова на странице, страница получает, допустим, 100 баллов. "Коттедж" - более частое слово в базе. И за наличие этого слова на странице страница получит только 50 баллов. Слово "аренда" - очень частое слово. За то, что оно встретилось на страница - страница получает 10 баллов. И здесь появляется понятие кворум.
Кворум это некоторая сумма баллов, которую должна набрать страница, чтобы появиться в выдаче по запросу.
Предположим, что в примере кворум 70 баллов. Посмотрим, какие документы пройдут в такую выдачу:
Если в документе встретиться один раз слово Savitaipale (очень редкое слово) то страница сразу получила 100 баллов и попадает в выдачу.
В другом документе встретилось вот такое предложение: "предлагаем коттеджи в аренду и аренду лодки бесплатно". Документ получает 50 баллов за "коттедж" и два раза по 10 баллов за "аренду".
Т.е. он набирает 70 баллов и окажется в выдаче.
Ещё вариант: в документе есть слова "снять" и "Савитайпале". За "снять" (как синоним "аренды") документ получает 10 баллов. За "Савитайпале" получает 100 баллов. В результате документ набрал 110 баллов и, конечно, оказался в выдаче.
Если же в документе встречается только слово "коттедж" или только слова "аренда", то по баллам он не набирает проходной балл и в выдачу не пройдет.
КВОРУМ С УЧЕТОМ РАССТОЯНИЯ МЕЖДУ СЛОВАМИ ЗАПРОСА
Еще одним ограничением на прохождение "кворума" и попадание в выдачу в Яндексе было заявлено ограничение на расстояние между словами в документе. В зависимости от конкретного запроса.
- в самом простом случае условие - слова запроса есть в документе, в любом его месте;
- более узкая ситуация, когда слова запроса должны встретиться обязательно в рамках одного предложения;
- еще уже - слова запроса на расстоянии друг от друга не более, чем два слова или непосредственно рядом, но в любой последовательности;
- самая жесткая ситуации - когда слова запроса должны встретиться ровно так же, как в запросе, строго в той же последовательности и той же морфологической форме (фразовый поиск).
Практическая польза для вас от всего этого в том, что когда вы будете заниматься поисковым продвижением и изучать конкурентов - документы, которые уже есть в выдачи по интересующему вас запросу, вы будете понимать: вот этот документ попал выдачу, потому что в нем используются редкие слова из запроса, их много и они находятся в рамках одного предложения с другими словами запроса. Для вас это будет значить, что вам нужно тоже использовать редкие слова.
Здесь табличка из инструкций Яндекса - вы видите еще два пункта относительно того, как Яндекс отбирает документы для выдачи:
1. Яндекс может добавить документ по наличию слов запроса в тексте входящей ссылки. Вы зашли на некоторый сайт - там стоит кликабельная ссылка "аренда коттеджей". Вы на неё нажали и перешли на наш сайт. Вот эти слова из ссылки (они называются "анкором" ссылки) Яндекс как-бы добавляет к нашему документу. И может найти документ по наличию ключевых слов в текстах ссылок. Раньше это был весьма эффективный способ продвижения. Сейчас былой эффективности нет, но механизм остался.
2. Ещё один механизм - технология семантического поиска. Называлась она "Королёв". Смысл этой технологии в том, что есть некоторый документ, который не содержит слов запроса. Но посвящен той же тематике, что и тематика запроса, и содержит тематические слова, семантически связанные с исходным запросом. И может быть полезен для пользователей Яндекса, раскрывая тему запроса, но не используя слова запроса.
Вот такие документы тоже могут попадать в выдачу Яндекса. Ввернулись к нашей табличке.
"Что может быть чуть менее очевидно — аналогично запросу можно «расширять» и документ, собирая для него «альтернативные» тексты, которые в Яндексе называют словом стримы (от англ. stream). Например, стрим для документа может состоять из всех текстов входящих ссылок или из всех текстов запросов в поиск, по которым пользователи часто выбирают этот документ на выдаче."
3. РАНЖИРОВАНИЕ (СОРТИРОВКА ПО РЕЛЕВАНТНОСТИ) ОТОБРАННЫХ ДОКУМЕНТОВ (СТРАНИЦ) С ПОСЛЕДУЮЩЕЙ ГРУППИРОВКОЙ ПО ДОМЕНАМ
В данном руководстве слова "страницы" и "документы" используем как синонимы. А так же считать синонимами слова "домен" и "сайт".
Отобраные релевантные запросу документы - Яндекс далее сортирует (ранжирует) эти страницы по релевантности
Отранжировав страницы, Яндекс группируют их по доменам таким образом, чтобы от каждого домена в поиске была видна только одна страница.
На этапе группировки Яндекс может поменять приоритетность некоторых страниц сайта так, что представлять сайт в поиске будет не та его страница, которая была наиболее релевантна запросу. А, например, страница с лучшими поведенческими характеристиками. Или самая релевантная страница сайта получит наказание за спам и вместо неё сайт будет представлен в выдаче другой страницей.
После группировки релевантных страниц по доменам Яндекс опять частично меняет выдачу - добавляя бонусы и повышая позиции одним сайтам и добавляя наказания и понижая позиции другим. Это принято называть "постфильтрами".
Есть несколько способов посмотреть выдчу релевантных страниц без группировки. И с разным участием постфильтров. Это можно сделать на Яндексе добавляя к урл параметр pag=u, поиском по группе сайтов из ТОП или с помощью сервиса Yandex XML. На Гугле можно посмотреть несгруппированную выдачу добавляя к урл параметр filter=0 или поиском по группе сайтов из ТОП.
Смотрим пример "аренда коттеджей". Получили выдачу - в каждом блоке найденного сайта мы видим один домен и одну страницу с этого домена.
Далее я использую мой внутренний сервис, который ищет с помощью Yandex XML.
Cначала мы будем искать так, как собственно и ищет привычный нам Яндекс - сразу с группировкой Яндексом. Вот что мы видим:
- на первом месте Авито, страничка снять коттедж;
- на втором месте страничка Циан, 462 объявления;
- на третьем месте вы видите "абракадабру" - так показывается русскоязычные названия домена "сутки-дом";
- на четвертом месте мой проект.
Т.е. есть выдача Yandex XML такая же, как и на обычном Яндексе. Данный вид поиска в параметрах называется "поиск с группировкой".
4. ПЛОСКИЙ ПОИСК В ЯНДЕКСЕ
Теперь мы будем использовать поиск по страницам без группировки - в Яндексе этот параметр называется "плоский поиск". В этом поиске мы уже видим, что выдача отличается:
- на первом месте та же самая страница Авито, которую мы видим здесь на первом экране;
- на втором месте - еще одна страница Авито (о которой, обычно, никто не узнает в общедоступном поиске);
- на третьем месте - та же страница Циана (второе место слева);
- 4 и 5 позиции - опять страницы Авито...
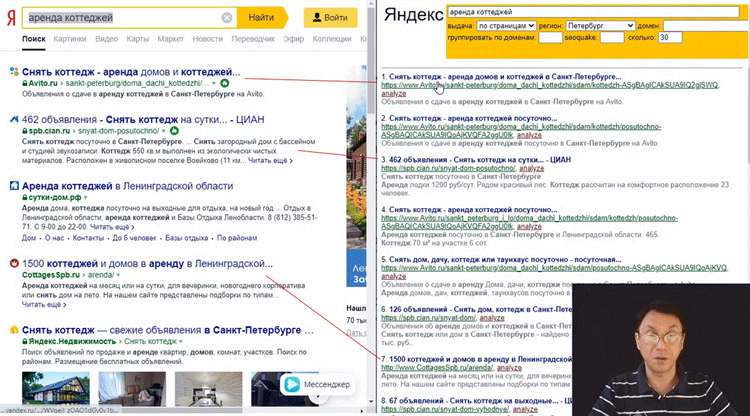
Вот реальное ранжирование найденных документов Яндексом.
После "плоского поиска" Яндекс группирует найденные страницы по домену так, что под первую страницу с домена прячутся все остальные релевантные страницы с этого домена. В общедоступном поиске мы можем увидеть эти страницы вот здесь, если выберем "еще сайта".
Но при этом мы теряем возможность сравнить по релевантности эти страницы со страницами с другого домена.
В "плоском поиске" мы получаем гораздо больше информации о конкуренции, поскольку видим все страницы с топовых сайтов, которые лучше нашей страницы, которую мы хотим поднять из глубин наверх.
5. СРАВНЕНИЕ ГРУППИРОВКИ ПЛОСКОГО ПОИСКА И ВЫДАЧИ ЯНДЕКСА - НАБЛЮДАЕМ ПОСТФИЛЬТРЫ
Несколько лет назад группировка в Яндексе была простой и сгруппировав по доменам "плоскую выдачу" получался тот же ТОП сайтов, как и в основном поиске Яндекса.
Сейчас, как вы видите, другая картина:
- на первом месте так и осталось Авито;
- на втором месте Циан;
- на третьем месте здесь появился сайт "сутки-дом";
Но при простой группировке из плоского поиска этот сайт был только на шестом месте.
Т.е. есть кроме группировки на этом этапе Яндекс добавил бонус данному сайту. Предположительно за пользовательское поведение.
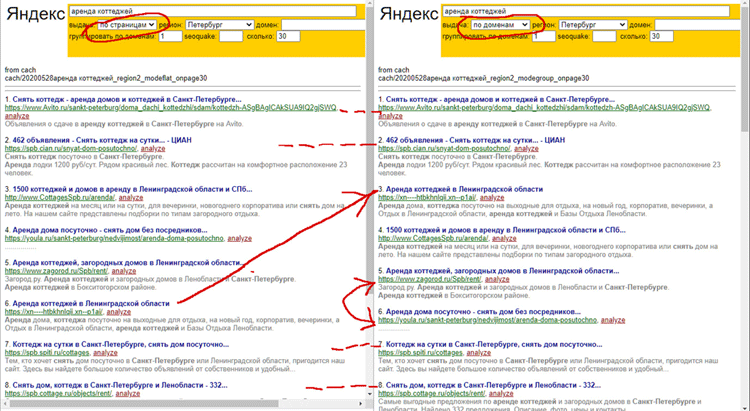
- мой сайт, который был на третьем месте, съехал на 4 место;
- сайт Юлы поменялся местами с сайтом Загород (эффект "однорукого бандита" с временным обменом их местами или бонус-наказание).
Сайты которые были на седьмых, восьмых местах - так и остались.
Таким образом, сравнивая самостоятельную группировку "плоской выдачи" и выдачу сразу с группировкой Яндексом мы можем видеть влияние постфильтров.
6. БЕСПЛАТНЫЕ ИНСТРУМЕНТЫ ДЛЯ ПОСТРАНИЧНОЙ ВЫДАЧИ
Сейчас я вам покажу несколько своих инструментов, которые позволяют смотреть несгруппированную выдачу Яндекса и Google.
В Яндексе для этого есть специальный параметр pag=U. Его нужно добавлять к адресной строке, после запроса. В Google и есть близкий по смыслу параметр filter=0.
Переходите на страничку моих букмарклетов, перетягиваете кнопку на панель закладок.

Для примера вводим в Яндексе запрос "аренда коттеджей". Ждем пока загрузится результат поиска. Нажимаем на кнопку букмарклета.
Посмотрите: скрипт букмарклета открыл результаты поиска в новой вкладке. И добавил к адресной строке параметр "не группировать выдачу".
Теперь очистим выдачу с помощью букмарклета для чистки выдачи из первого урока.
И вот у нас на экране в чистом виде постраничная выдача.