Урок 4: Оптимизация, переоптимизация и качество текста (13 мин.)
смотреть видеолекцию:
КОНСПЕКТ УРОКА:
ИНСТРУМЕНТЫ ПРОВЕРКИ ТЕКСТА НА ПЕРЕОПТИМИЗАЦИЮ
Существует несколько алгоритмов, которые позволяют отличать некачественный текст от качественного, переоптимизированный от естественного. Но точно, какие алгоритмы и с какими пороговыми значениями используется в Яндексе и Google - никто нам не скажет.
Популярные методы оценки качества текста представлены здесь, в верхней части схемы.
Эти методы реализованы в ряде инструментов для оптимизаторов:
- miratext.ru/seo_analiz_text
- seolik.ru/analysis-content
- advego.com/text/seo/
- turgenev.ashmanov.com
- copywritely.com
- readability.io
- text.ru/seo
- glvrd.ru
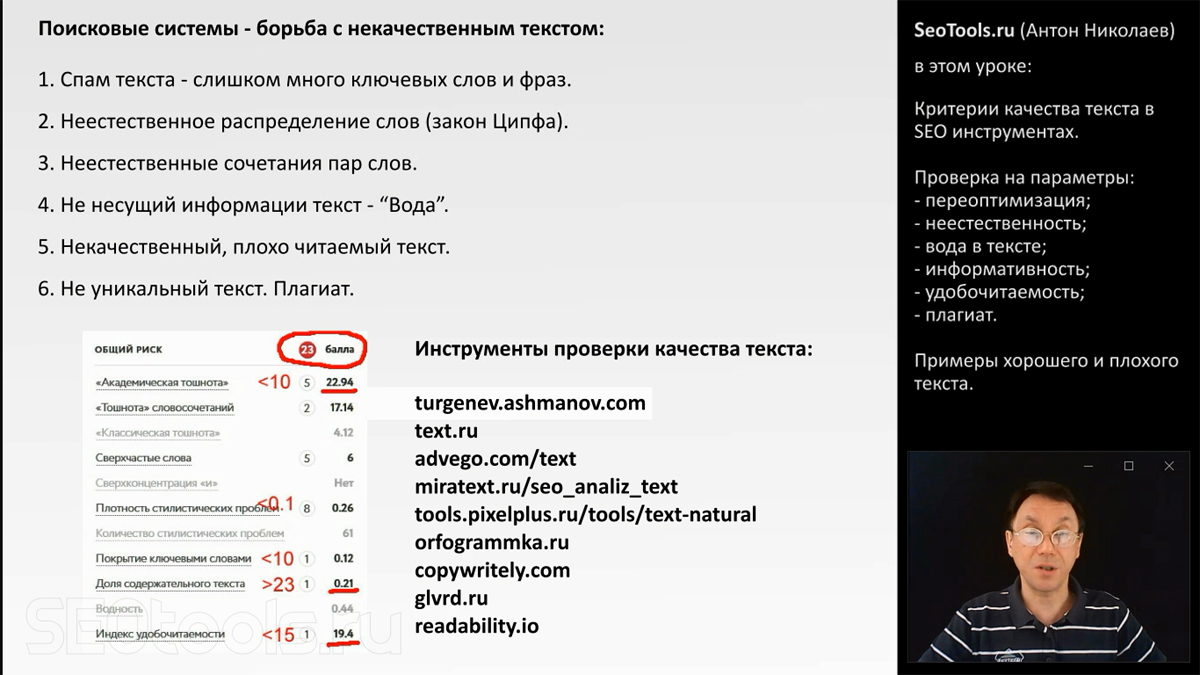
В качестве примера здесь вы видите часть экрана инструмента "Тургенев" - turgenev.ashmanov.com, в котором проанализирован ранее упомянутый пример переспама текст из блога Яндекса для веб-мастеров. Вы видите здесь, что текст набрал 23 балла риска попадания под наказание Яндекса. И подчернуты параметры, по которым этот текст превысил пороговое значение.
АКАДЕМИЧЕСКАЯ ТОШНОТА
Первый популярный метод - "академическая тошнота". Это отношение частоты употребления самого популярного слова в тексте, в различных морфологических формах, к общему количеству слов в тексте. Данный текст набрал 22 балла - пороговое значение для естественного текста в инструменте "Тургенев" - 10 баллов. По остальным параметрам я буду говорить дальше.
Ещё один инструмент, в котором проанализирован образец текста с переспамом - copywritely.com. Вы видите общую оценку "плохо". В основном - переспам. Здесь выделены на розовом фоне слова, которые имеют слишком высокую частоту употребления и приводят к такой оценке. Также здесь оценивается: грамматика, читабельность, водянистой фраз - об это будет в дальнейшем.
Теперь покажу вам "хороший", естественный текст. Текст, который получил оценку "хорошо". Никакого переспам, текст написан короткими предложениями (что повышает его читабельность), простыми словами - вот такие тексты "любят" инструменты для оптимизаторов.
ЕСТЕСТВЕННОЕ РАСПРЕДЕЛЕНИЕ СЛОВ ПО ЗАКОНУ ЦИПФА
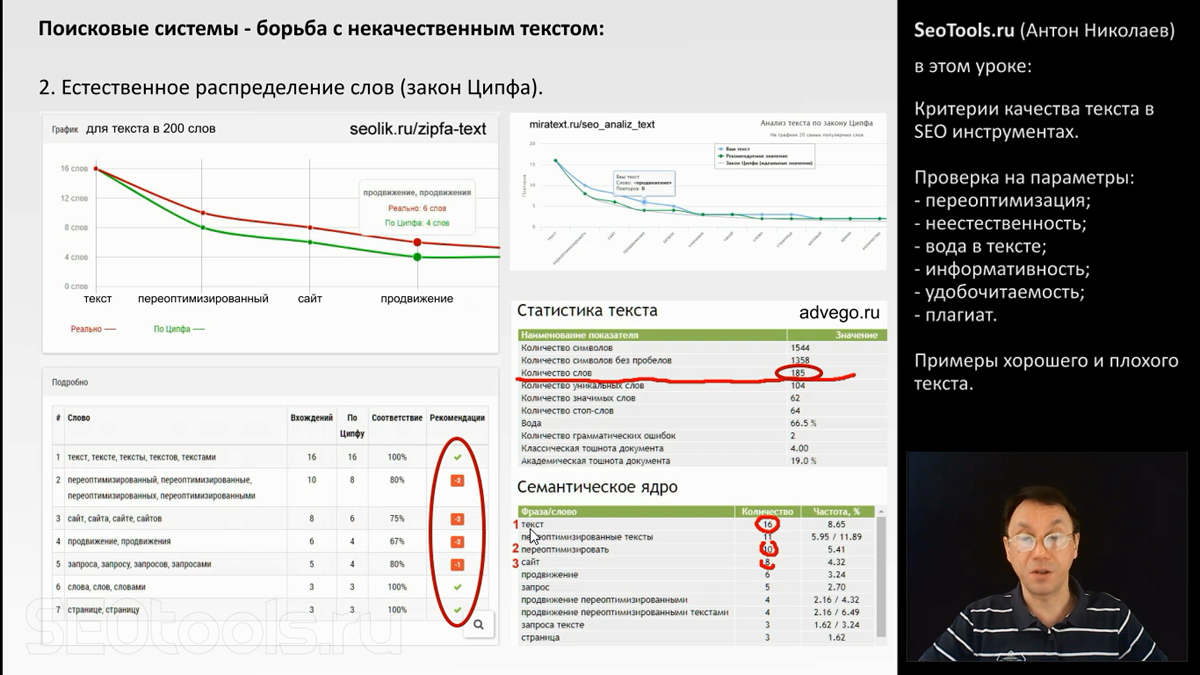
Продолжаем исследовать переспам. Для анализа естественности текст в данном примере используется закон естественного распределения слов (Ципфа, Зипфа), который связывает три параметра: количество слов в тексте, количество употреблений слова в тексте и ранг слова по популярности.
Самое популярное слово имеет 1 ранг, второе по популярности имеет 2 ранг, третье по популярности - 3 ранг и так далее. Для каждого языка получается свое естественное распределение частоты употребления слова в зависимости от ранга и числа слов в тексте.
В данном примере используется несколько инструментов:
- miratext.ru/seo_analiz_text
- seolik.ru/zipfa-text
- advego.ru
Первое, самое популярное слово текста, используется 16 раз в тексте размером около двухсот слов. Столько и должно быть по закону Ципфа.
Второе по популярности слово "переоптимизированный" в разных морфологических вариантах должно встречаться по закону естественности языка 8 раз. Здесь в тексте оно использовано 10 раз. Данный инструмент дает рекомендацию: чтобы текст выглядел естественно, нужно убрать два этих слова.
И так далее: слово "продвижение" по закону должно использоваться четыре раза для такого объема текста, а используется шесть раз.
Данный закон наиболее четко работает на больших текстах. На коротких текстах он может и не всегда выявлять неестественные тексты. Но, тем не менее, всегда полезно сравнить свой текст статьи с естественным распределением слов и посмотреть отличия. Поскольку поисковая система также может использовать этот алгоритм.
НЕЕСТЕСТВЕННЫЕ ПАРЫ СЛОВ
Следующий метод выявления неестественных текстов был опубликован сотрудниками Яндекса достаточно давно. Он заключается в выявлении в тексте неестественных пар слов - сочетаний слов, которые в естественном языке нигде не встречаются. Как по несогласованности по грамматике, так и по статистике (эти слова рядом не употребляются). Кроме вот такого грубого примера, как на изображении, встречаются попытки в тайтл документов ставить максимальное количество ключевых слов, при том что нарушается естественность их сочетания.
ВОДНОСТЬ ТЕКСТА
Следующий параметр, на который текст проверяют многие популярные инструменты оптимизаторов - это "водность". Т.е. использование не несущих смысловой нагрузки слов, которыми разбавляют основной текст для увеличению его объема. Лично мне нравится вот инструмент: "Главред" (glvrd.ru), который анализирует текст на много параметров, включая литературность - и выдает итоговую оценку.
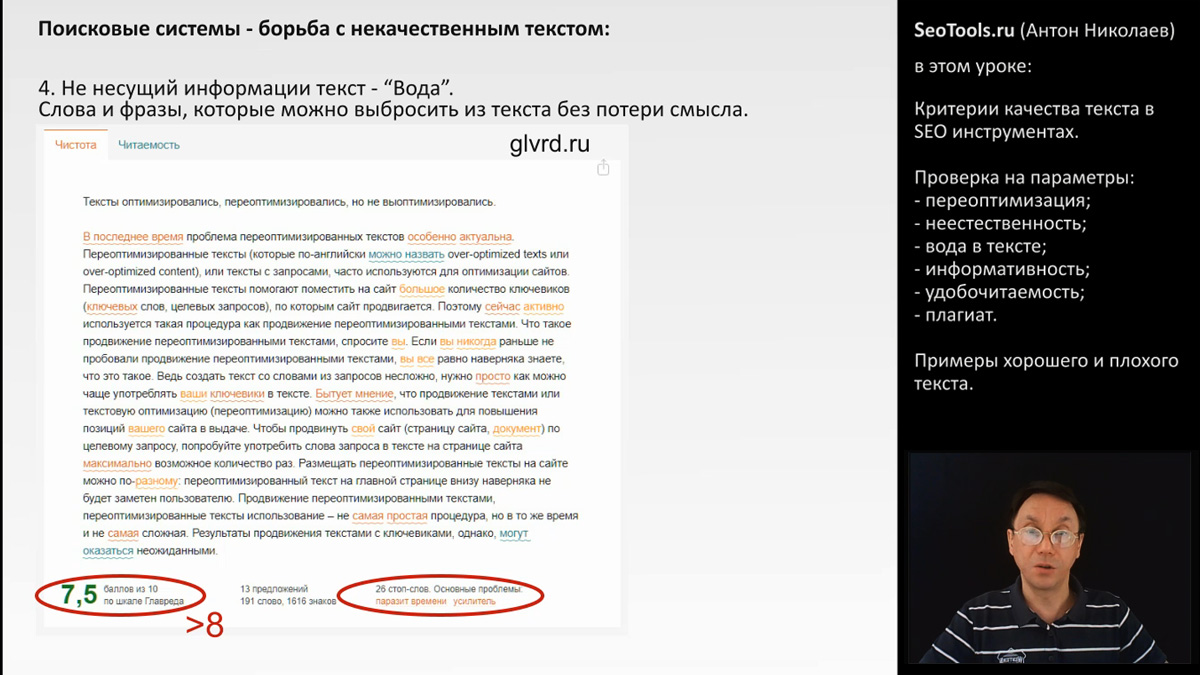
Я проверял статьи из качественных журналов, и все тексты имели оценку не менее 8 баллов.
Данный переоптимизированный текст имеет оценку 7.5
И это может быть для поисковых систем одним из признаков, чтобы посчитать текст некачественным.
Одной из формулировок наказаний Яндекса с понижением позиции сайта - "за малополезный контент". "Водность" может быть одним из признаков такого контента.
Давайте ещё раз посмотрим инструмент "Тургенев". У переоптимизированного текста выделены слова, которые данный инструмент посчитал водными. Кроме параметра "водности" (здесь он 44) есть еще и параметр "доля содержательного текста". По этому инструменту доля "содержательного текста" должна быть больше 23. У примера спамтекста - 21. Т.е. он не проходит границу и по этому параметру.
Теперь покажу пример формально хорошего текста, который проходит большинство пороговых значений. Вот этот текст. Доля "содержательного текста" 58, т.е. в два раза выше, чем пороговое значение. Более чем в два раза выше, чем доля "содержательного текста" в предыдущем примере переоптимизации. Очень хороший индекс читабельности - 4 (при том, что должен быть не больше 15) и достаточно низкая "водность" - 35.
ФОРМАЛЬНАЯ СЛОЖНОСТЬ ТЕКСТА ДЛЯ ЧТЕНИЯ
Последний параметр качества текста, который используется в ряде инструментов для оптимизаторов, связан со специфическими коэффициентами, отражающими сложность сложности текста для чтения. Он зависит от количества длинных слов и длинных предложений. Этот метод используется в нескольких инструментах. Вот здесь вы видите их названия:
- turgenev.ashmanov.com
- orfogrammka.ru
- readability.io
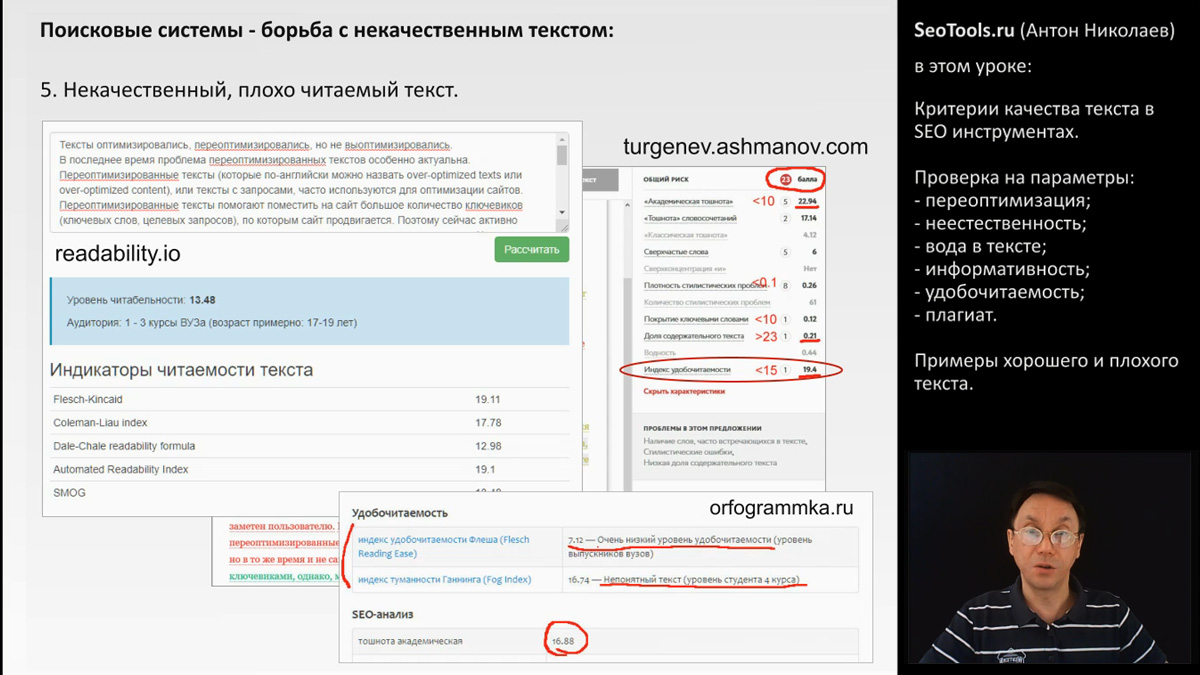
Вводим сюда переоптимизированный текст из примера Яндекса.
Техт не проходит пороговое значение на сервисе "Тургенев" по индексу удобочитаемости - 19 (при пороге в 15).
Сервис "Орфограммка" тоже дает низкий уровень удобочитаемости.
Сервис Readability указывает, что аудитория, которой доступен данный текст - это студенты вузов. А так же показывает конкретные значения параметров текста по нескольким популярным методикам: Flesch-Kincaid, Coleman-Liau index, Dale-Chale readability formula, SMOG.
Резюме по удобочитаемости: хорошо читаемый текст, это достаточно короткие предложения, короткие понятные фразы и отсутствие переспама. Пример текста с хорошим индексом удобочитаемости и очень высоким баллом Главреда.
УНИКАЛЬНОСТЬ ТЕКСТА. ПЛАГИАТ. МЕТОД ШИНГЛОВ.
Последний признак "некачественного" текста, о котором я расскажу (который используется в поисковых системах и в инструментах для оптимизаторов), это "уникальность текста". Поисковые системы декларируют, что дубли текста (плагиат) не попадают в выдачу, потому что не несут дополнительной пользы для посетителей.
Как выявляются дубли. Ниже будет пример метода шинглов, который был опубликован сотрудниками Яндекса. Берем фразу, разбиваем ее на пары по два слова (можно и по 4, и по 6 - но данном примере по 2) и ищем повторение этих пар в другом тексте. В примере вы ыидите, что найдено 4 совпадения. Таким образом, второй текст получился не совсем уникальным. На практике поисковые системы часто поднимают копии текста, размещенные на авторитетных сайтах, а первоисточник на слабом сайте может быть вообще удален из выдачи.
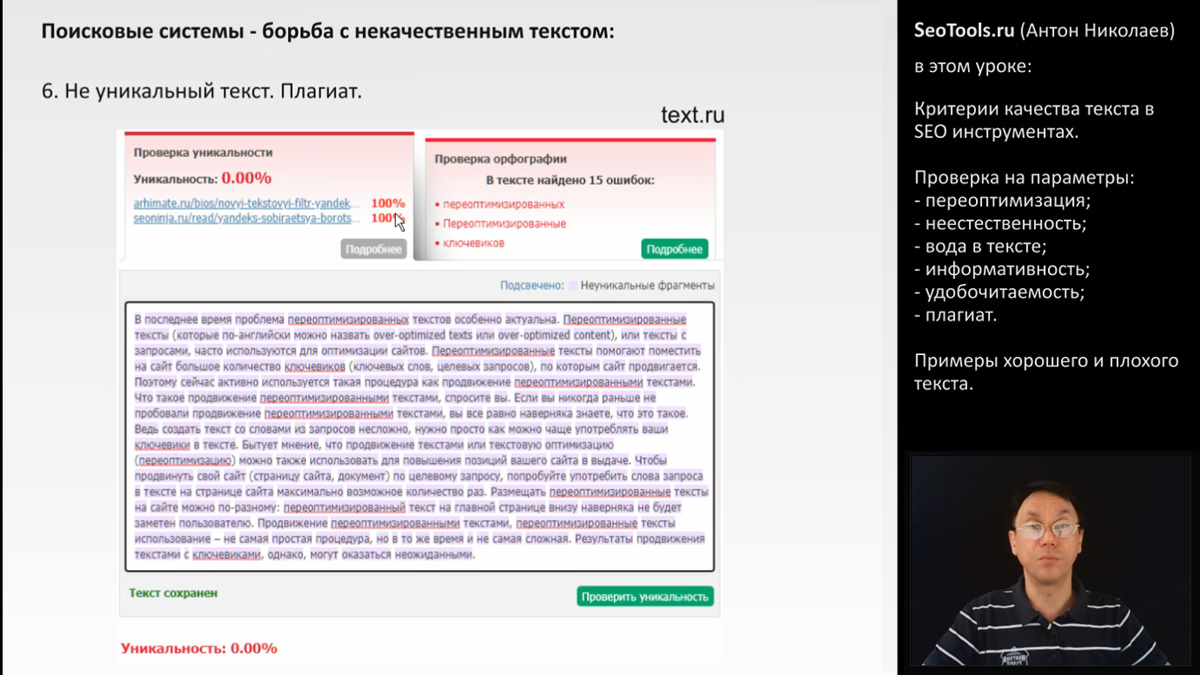
Перед вами пример анализа на уникальность текста с помощью сервиса text.ru
Вот он проверен и на двух сайтах найдены полные копии этого текста. Таким образом, уникальность этого текста равна 0 процентов.
