Урок 17: Кластеризация, отбор запросов и контент посадочной страницы (26 мин.)
смотреть видеолекцию: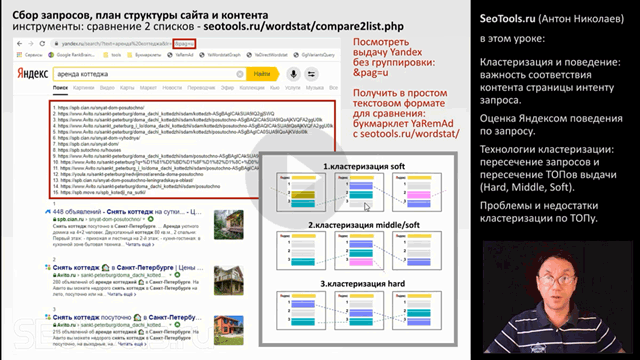
КОНСПЕКТ УРОКА:
Добрый день. На прошлых уроках мы изучали с вами методы и инструменты сбора запросов и их частотности.
Теперь у нас будет несколько уроков про то, как создать структуру сайта из посадочных страниц (landing pages) - страниц, на которые мы будем "сажать" посетителей с поисковых систем по конкретным запросам. И как выделить группу запросов для каждой такой страницы.
Посмотрите на экране "путь посетителя сайта":
1. Посетитель задает в поиске запрос.
2. Этот запрос имеет под собой некоторый интент, потребность (так, что одни слова в поисковом запросе могут выражать разные интенты и один интент может быть выражен разными словами в запросе).
3. Посетитель видит сниппеты в выдаче и на их основании принимает решение на какой сайт перейти.
4. Посетитель попадает на посадочную страницу и принимает решение: остаться на сайте или закрыть и вернуться в поиск.
5. Если посадочная страница понравилась - посетитель посещает другие страницы сайта.
Я хочу напомнить вам про важность поведенческих факторов в ранжировании поисковых систем. Часть факторов связана с поведением посетителя на посадочной странице - если он не вернулся обратно в поиск, значит там ответ на интент его запроса. Если он вернулся в поиск: чем больше времени он провел на сайте - тем больше сайт соответствует запросу. Еще важные показатели:
- количество страниц с долгими просмотрами;
- попадание сайта (страницы) в закладки;
- постоянство аудитории - возвраты на сайт;
С 2015 года официальный алгоритм Яндекса:
- сначала подбираются релевантные страницы;
- потом они постоянно проверяются на пользовательское поведение и в зависимости от пользовательского поведения ранжируются в выдаче.
Двигаясь по типовому пути посетитель будет постоянно сравнивать то, что увидел на вашем сайте с сайтами конкурентов. В выдаче - сравнивать ваш сниппет со сниппетами конкурентов. На посадочной странице - с тем, что видел на посадочных страницах конкурентов.
Я повторно делаю на этом акцент, чтобы вы хорошо понимали - только семантикой хорошее пользовательское поведение не сделать. За семантикой должно быть решение потребности пользователя. Причем лучше, чем у конкурентов.
Когда вы готовите страницу и выбираете запросы для её продвижения - вы должны подумать о соответствии контента интенту каждого из этих запросов. И конкурентных преимуществах вашего контента перед аналогичным контентом конкурентов.
Если у вас уже есть готовый сайт, то можно посмотреть, наксколько посетители удовлетворены контентом по конкретному запросу. И как Яндекс оценивает поведение посетителя по пятибальной шкале.
Вебвизард в Яндекс-Метрике
На экране:
- одна строка отражает одного посетителя;
- можно отфильтровать посетителей по многим параметрам;
- есть колонка с запросом по которому посетитель пришел из Яндекса;
- есть колонка оценки Яндексом активности посетителя по 5-бальной шкале;
Пример. Рамочкой выделено поведение трех посетителей, пришедших на посадочную страничку (оптимизированную под интент "аренда коттеджей на берегу озера") по соответствующим запросам. Вы видите по 5 зеленых точечек у каждого посетителя. Это и есть оценка их поведения Яндексом.
Очевидно хорошее поведение:
- просмотренных страниц больше одной;
- среднее время на странице - больше минуты;
А это пример очень плохого поведения посетителя:
- посмотрел только одну страницу;
- время просмотра девять секунд.
Т.е. практически сразу он ушел. Возможно даже не дождавшись полной загрузки страницы. За этого посетить сайт получил от Яндекса единицу по нужному запросу.
Обратите внимание, что в этой колоночке указан браузер посетителя. Он заходил из Яндекс-Браузера, от которого Яндекс получает поведенческую информацию.
Такое плохое поведение мы получаем если:
1. У нас реально слабый контент или неинтересный товар (вспомните критерии ассессоров).
2. Сайт медленно открывался или неудобен на смартфонах (вспомните про технические параметры загрузки сайта).
3. На наш сайт проводится атака конкурентов, которые симулируют негативное поведение, чтобы понизить наш сайт в выдаче. Особенно, если плохое поведение идет:
- от мобильного пользователя;
- через Яндекс-Браузер или Яндекс-Приложение;
- из регионов, не соответствующих нашей региональности.
Все эти параметры можно посмотреть в Вебвизоре.
Пример соответствия интента запроса и контента страницы.
Два урока назад мы создавали список страниц с маркерами и подбирали к ним запросы.
Посмотрим на два запроса "домик на берегу озера" и "дом на берегу озера".
Уместно ли их помещать в один кластер?
Если они попадут на одну страницу, то будет крайне трудно сделать корректный контент для этой страницы. Поскольку "домик" и "дом" - это разные вещи на рынке аренды недвижимости. Это разный интент запроса и разная ЦА - целевая аудитория.
"Домик" ищут пары или молодая семья с ребенком за бюджетную цену.
"Дом на берегу озера" может быть:
- под большую компанию с бюджетом вскладчину;
- под семью с хорошим бюджетом и высокой требовательностью качеству.
Для лучшего поведения, под каждую из этих целевых аудиторий мы должны сделать отдельную посадочную страницу с контентом, соответствующим интенту запроса этой ЦА.
Разделить интент и ЦА при одинаковом запросе "Дом на берегу озера" мы не можем технически.
Но выделить запросы с "домиком" - можем легко.
Этот пример с "домом" и "домиком" я буду вам часто приводить, показывая работу автоматических кластеризаторов.
Напомню про эту иллюстрацию: посетитель переходит на вашу страницу из поиска и у него в голове есть потребность. Попав на посадочную страницу - по текстам и изображением он должен сразу понять, что попал в правильное место.
Вернемя к кластеризации. Далее на уроке я буду показывать вам, как различные автоматизированные классификаторы справляются с задачей на том же наборе запросов, как в этом примере. В идеале - получить максимально близкий состав страниц и запросов к каждой из них, как в ручной группировке. Напомню, что большинство кластеризаторов действует по единой схеме:
- получают по запросу выдачу ТОП10 в сгруппированном виде;
- смотрят наличие одной страницы в ТОПах по двум запросам;
- если находят - относят запросы к одному кластеру.
Arsenkin Tools
Первый сервис по кластеризации это кластеризатор от Арсенкина (arsenkin.ru/tools/clustering/) Здесь не бесплатно, но недорого и добротно.
Смотрим на интерфейс:
- поле для ввода списка запросов;
- выбираем поисковую систему;
- регион (что есть не во всех сервисах по кластеризации);
- метод группировки (по умолчанию hard).
Справа таблица, объясняющие названия методов группировки.
Каждый прямоугольничек - это выдача по одному запросу из трех разных.
Метод hard. Если по трем запросам в ТОПе встречаются ссылки на один и тот же документ (обозначен одинаковым цвтом) - значит эти три запроса можно объединить в группу (кластер) и продвигать на одной странице.
Метод soft. Метод предполагает попарное сравнение страниц. Вот эти два запроса можно объединить в кластер, потому что у них есть общие урл в выдаче. У страници выдачи по второму запросу есть общий урл с вот этой страницей выдачи - поэтому она тоже может попасть в этот класте. А также в него может попасть запрос, на странице выдачи которого будет общий url с страницей выдачи по первому запросу и т.д.
Ещё встрачается метод кластеризации middle (хотя в некоторых кластеризаторах именно он называется soft). В этом методе однин запрос принимается за главный и все урл по другим запросам сравниваются с урл в выдаче по главному запросу.
Возвращаемся к настройкам. Можно выбрать силу группировки: чем больше цифра, тем больше должно быть общих урал, чтобы запросы могли попасть в один кластер.
Сложность настройки автоматической кластеризации заключается в том, что вы заранее не знаете, какие параметры выбирать чтобы у вас получилась правильная группировка запросов по страницам:
- с точки зрения возможности их продвижения на одной странице;
- с точки зрения контента, который должен быть ориентирован на пользовательскую потребность.
В учебных целях я буду оставлять в кластеризаторах дефолтные настройки и сравнивать с результатами ручной кластеризации по потребностям.
В результате кластеризации с помощью кластеризатора Арсенкина мы получаем таблицу, которую экспортируем в эксел. У нее есть колонки:
- поисковый запрос;
- название группы (один из запросов группы);
- общая частотность группы;
- процент сайтов-агрегаторов в выдаче по запросу;
Отвлечемся - это очень ценный параметр запроса, которого в других инструментах еще не было. Агрегаторами называется сайты, которые агрегирует предложение из разных источников. Таким образом агрегатор сразу отличается большим разнообразием предложения и хорошим выбором для посетителя. Это дает хорошие поведенческие показатели. Если в выдаче агрегаторов много - продвигаться будет сложно. Особенно сайт - не агрегатор.
С помощью инструмента эксел "сводная таблица" строим дополнительную табличку в которой есть название группы и сколько запросов в нее попали - она нам понадобиться в дальнейшем.
"Некластеризовано" - ни в какую группу не попало 20 запросов.
К сожаленю,в этом инструменте есть серьезная проблема с "Суммарной частотой".
Пример. В группу "коттедж снять" попали три фразы: "коттедж снять", "снять коттедж" и "аренда коттеджа". Их частоты указаны как:
- коттедж снять = 20278;
- снять коттедж = 19964;
- аренда коттеджа = 10362;
Сумма = 50604.
Но это не запросы, а наборы слов, по которым показывается реклама. Здесь они некорректно названы запросами, хотя даже получены из Яндекс-Вордстат без точной формы. Об этом говорит прямое сравнение с частотностью в скриншоте Вордстат (чуть выше). Вордстат дал:
- коттедж снять = 20278;
- снять коттедж = 20278 (посчитаны второй раз те же показы, что и выше);
- аренда коттеджа = 10362;
Сумма показов будет = 20278+10362 = 30640.
Это без учета показов по запросам, в которых присутствуют одновременно "снять" и "аренда". Итого тут останется около 30000 показов.
Как мы знаем, число запросов всегда меньше числа показов за счет "глубины просмотра".
Сравнение с ручной кластеризацией
Перед вами результаты кластеризации:
- ручная кластеризация;
- кластеризация по Яндекс;
- кластеризация по Google.
Желтым здесь выделены тематический кластеры, страницы - которые не были выявлены кластеризатором. Синим отмечаю кластер, которые кластеризатор вынес на отдельную страницу, но по логике товарного предложения они должны попадать в уже существующий кластер - дублирование кластера.
Пример на экране, кластеры "коттеджи в ленинградской области" и "снять дом в области". Это самые общие запросы в нашей теме. Здесь будет и интент долгосрочной аренды, и интент краткосрочной аренды. И более узкие интенты. Для хороших поведенческих такую общую страницу коммерческого сайта нужно собрать из наиболее привлекательных объектов разных интентов - которых у нас будет только один комплект.
Если разделить на две страницы согласно предложению кластеризатора, то придется:
- либо продублировать один контент на две страницы, что очевидно плохо для поисковиков (неуникальный контент);
- либо разделить объекты на два контента, разбавив их менее привлекательными, что ухудшить поведенческие.
В обоих случаях будет плохо для посетителей - две страницы с одним, по сути, контентом...
Можно понять, почему кластеризатор разделил эти запросы. Первый из них - это мультиинтентный запрос, в нем есть интент "купить" и интент "снять". И часть ТОПа по запросу заняли сайты по продаже. Но у нас нет такой услуги, так что остается делать контент только для интента "снять".
Второй пример, запрос "снять коттедж петергоф". В этом запросе важнейшее ключевое слово - топоним "петергоф". Это обязательное условие для интента пользователя. И под этот интент для поведенческих нужен соответствующий контент. К сожалению, кластеризатор это не распознал и нам не предложил.
В результе мы имеем две проблемы:
1. Предложение дублировать контент.
2. Потеря кластеров, которые обязательно нужны по интенту пользователей.
Не проводя анализ запросов вручную, мы даже не догадаемся, что имеем эти проблемы.
Автоматическая кластеризация по ТОПам экономит время оптимизаторов. Но дает весьма посредственный результат для конечного клиента.
Перед вами цены на сервис кластеризации Arsenkin Tools. Кластеризатор не входит в бесплатный пакет.
Проверка кластеризации по ключевым словам
Перед вами небольшой сервис на моем собственном сайте (seotools.ru/wordstat/check-clusters.php)
Он предназначен для проверки кластеризации, сделанной сторонними инструментами.
В это поле вы вводите скопированную из экселовской таблицы кластеризацию.
Первая колоночка - название кластера.
Вторая колоночка - запрос.
Разделитель - табуляция или знак равно.
Этот инструмент проверяет, какие ключевые слова из запросов попали в тот или иной кластер.
Пример: кластер "снять дом в карелии". Сюда попала 39 запросов с общей частотностью 194.
Первая строка - ключевые слова в алфавитном порядке (выделены жирным шрифтом).
Вторая - слова по частоте встречаемости в запросах.
Разбираясь в данной тематике я понимаю, что это хорошо сформированный кластер, соответствующий потребностям клиента. Т.е. по этому кластеру можно сделать качественную страницу с хорошим контентом, который нигде дублироваться не будет.
А вот другие кластеры. Тут одни и те же слова попадают и в этот кластер, и в этот - и т.д. Т.е. эти 1, 2, 4, 5 страницы - для них не сделать уникального контента... они совершенно про одно и тоже. Про одну и ту же потребность, используя одни и те же слова. Предложить здесь посетителям разный контент будет практически невозможно. Поэтому надо вручную проверять и объединять в один кластер.
Но чтобы это понять, нужно сначала разобраться в данной теме и провести кластеризацию вручную...
Кластеризации по сгруппированной выдаче?
Во всех кластеризаторах, с которыми я работал есть странное решение (по крайней мере - на уровне документации).
Кластеризаторы ищут наличие ссылки на страницу в ТОПе по некоторому запросу. Наличие ссылки на эту же страницу в ТОПе по-другому запросу является основанием для объединения в кластер, так гарантирует возможность попадания в ТОП двух запросов на одной странице.
Однако, все они используют сгруппированный ТОП, теряя большую часть ссылок на страницы в реальном ТОПе.
Увидеть в ТОПе скрытые при группировке страницы достаточно просто:
В Яндексе к урл в адресной строке нужно добавить параметр pag=u
В Google добавить параметр filter=0
И вы получаете разгруппированную выдачу.
При этом в выдаче Яндекса понизятся сайты, поднявшиеся при группировке за счет доменного бонуса (я наблюдал такое с сайтами, занимавшимися накрутками поведенческих факторов) или однорукого бандита.
Вы можете воспользоваться специальным букмарклетом для Яндеса с моего сайта. Он кратко дублирует список найденных страниц в Яндексе над выдачей. И нумерует выдачу.
Получив в текстовом виде список страниц из ТОПа Яндекса, вы можете сравнить два таких списка найденных url инструментом у меня на сайте (seotools.ru/wordstat/compare2list.php)
Инструмент выделяет цветом те страницы, которые попали в оба списка.
В данном примере красными цифрами вы были выделены те страницы, которые попали в ТОП выдачи Яндекса после группировки. А серым - те url, которые попали в ТОП выдачи без группировки.
Посмотрите, вот здесь страница авито попала в оба ТОПа: здесь она на восьмом месте в разгруппированной выдаче, а тут она на двадцать втором месте. Т.е. два запроса можно продвигать на одной странице. В сгруппированной выдаче мы этой страницы вообще не видим. После группировки в первом списке авито представлено другой страницей, а во втором - третьей.
Этот пример хорошо иллюстрирует типовую проблему доступных кластеризаторов - потерю информации за счет использования для ТОПа сгруппированной выдачи.
